

One of the advantages of having a lot of unique hobbies is that they wire your brain a little differently. You will find yourself approaching problems from a different angle as you mentally cross-contaminate different domains. As a semi-active Paramedic, I find tons of parallels between responding to meat-bag emergencies and managing bits-and-bytes emergencies.
I’ve been teaching a lot of cloud incident response over the past few years and started using two phrases from Paramedicland that seem to resonate well with budding incident responders. These memory aids do a good job of helping refine focus and optimizing the process. While they apply to any incident response, I find they play a larger role on the cloud side due to the inherent differences caused predominantly by the existence of the management plane.
Sick or Not Sick
Paramedics can do a lot compared to someone off the street, but we are pretty limited in the realm of medicine. We are exquisitely trained to rapidly recognize threats to life and limb, be they medical or trauma, and to stabilize and transport patients to definitive care. One key phrase that gets hammered into us is “sick or not sick.” It’s a memory aid to help us remember to focus on the big picture and figure out if the patient is in deep trouble.
I love using this one to help infosec professionals gauge how bad an incident is. For cloud, we teach them to identify significant findings that require them to hone in on a problem right then and there before moving on. In EMS, it’s called a “life threat.” Since cloud incident response leverages existing IR skills with a new underlying technology, that phrase is just a reminder to consider the consequences of a finding that may not normally trigger a responder’s instincts. Here are some simple examples:
- Data made public in object storage (S3) that shouldn’t be.
- A potentially compromised IAM entity with admin or other high privileges.
- Multiple successful API calls using different IAM users from the same unknown IP address.
- Cross-account sharing of an image or snapshot with an unknown account.
- A potentially compromised instance/VM that has IAM privileges.
When I write them out, most responders go, “duh, that’s obvious,” but in my experience, traditional responders need a little time to recognize these issues and realize they are far more critical than the average compromised virtual machine.
“Sick or not sick” in the cloud almost always translates to “is it public or did they move into the management plane (IAM).”
Sick or not sick. Every time you find a new piece of evidence, a new piece of the puzzle, run this through your head to figure out if your patient is about to crash, or if they just have the sniffles.
Stop the Bleed
Many of you have probably taken a CPR and First Aid class. You likely learned the “ABCs”: Airway, Breathing, and Circulation.
Yeah, it turns out we really screwed that one up.
Research started to show that, in an emergency, people would focus on the ABCs to the exclusion of the bigger picture. Even paramedics would get caught performing CPR on someone who was bleeding out from a wound to their leg. Sometimes it was perfect CPR. You could tell by how quickly the patient ran out of blood. These days we add “treat life threat” to the beginning, and “stop the bleed” is the top priority.
See where I’m headed?
In every class I’ve taught, I find highly experienced responders focusing on their analysis and investigation while the cloud is bleeding out in front of them. Why?
Because they aren’t used to everything (potentially) being on the Internet. The entire management plane is on the Internet, so if an attacker gets credentials, you can’t stop them with a firewall or by shutting down access to a server. If something is compromised and exposed, it’s compromised and exposed to… well, potentially everyone, everywhere, all at once.
Stop the bleed goes hand in hand with sick or not sick. If you find something sick, do you need to contain it right then and there before you move on? It’s a delicate balance because if you make the wrong call, you might be wasting precious time as the attacker continues to progress. Stop the bleed equals “this is so bad I need to fix it now.” But once you do stop the bleed, you need to jump right back in where you were and continue with your analysis and response process since there may still be a lot of badness going on.
My shortlist?
- Any IAM entity with high privileges that appears compromised.
- Sensitive data that is somehow public.
- Cross-account/subscription/project sharing or access to an unknown destination.
There’s more, but that’s the shortlist. Every one of these indicates active data loss or compromise and you need to contain them right away.
Seeing it in Action
Here’s an example. The screenshots are a mix of Slack, the AWS Console, and FireMon Cloud Defense. That’s my toolchain, and this will work with whatever you have. In the training classes, we also use Athena queries to simulate a SIEM, but I want to keep this post short(ish).
Let’s start with a medium-severity alert in Slack from our combined CSPM/CDR platform:
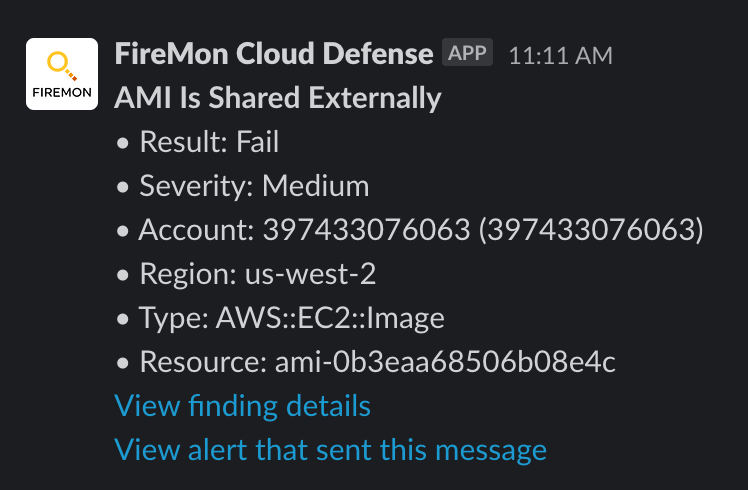
Sick or Not Sick? We don’t know yet. This could be totally legitimate. Okay, time to investigate. I’ll show this both in the platform and in the AWS console. My first step is to see what is shared where. Since the alert has the AMI ID, we can jump right to it:
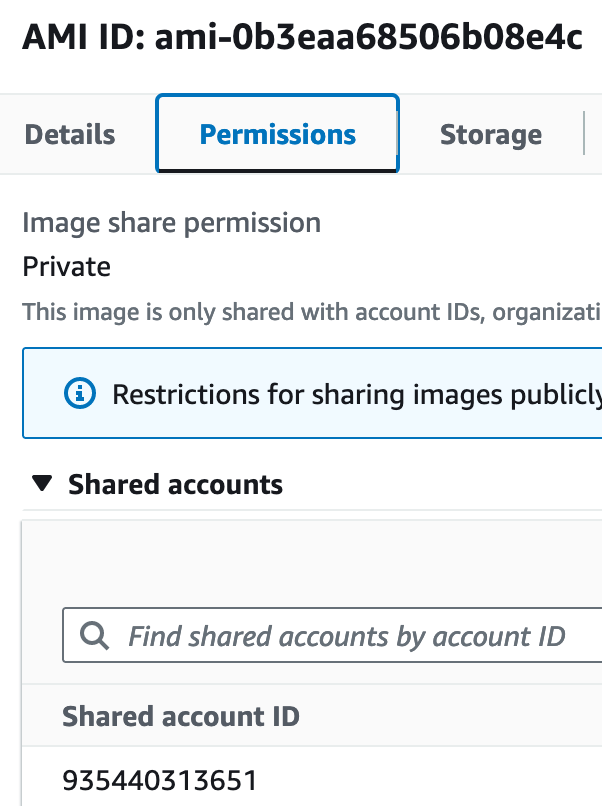
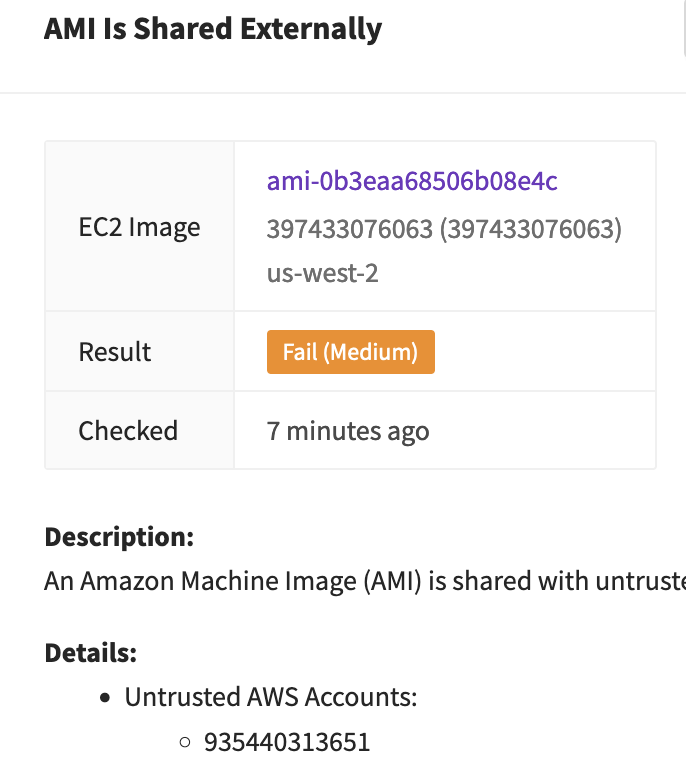
Okay- I can see this is shared with another account. Is that an account I own? That I know? My tool flags it as untrusted since it isn’t an account registered with the system, but in real life, I would want to check my organization’s master account list just to double-check.
Okay, sick or not sick? In my head, it’s still a maybe. I have a shared image to a potentially untrusted account. But I don’t know what is shared yet. I need to trace that back to the source instance. I’m not bothering with full forensics; I’m going to rely on contextual information since I need to figure this out pretty quickly. In this case, we lucked out:

It has “Prod” in the name, so… I’m calling this “probably sick.” Stop the bleed? In real life, I’d try to contact whoever owned that AWS account first, but for today, I do think I have enough information to quarantine the AMI. Here’s how in the console and Cloud Defense:
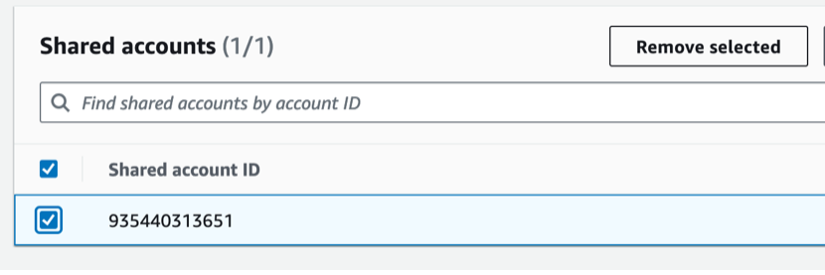
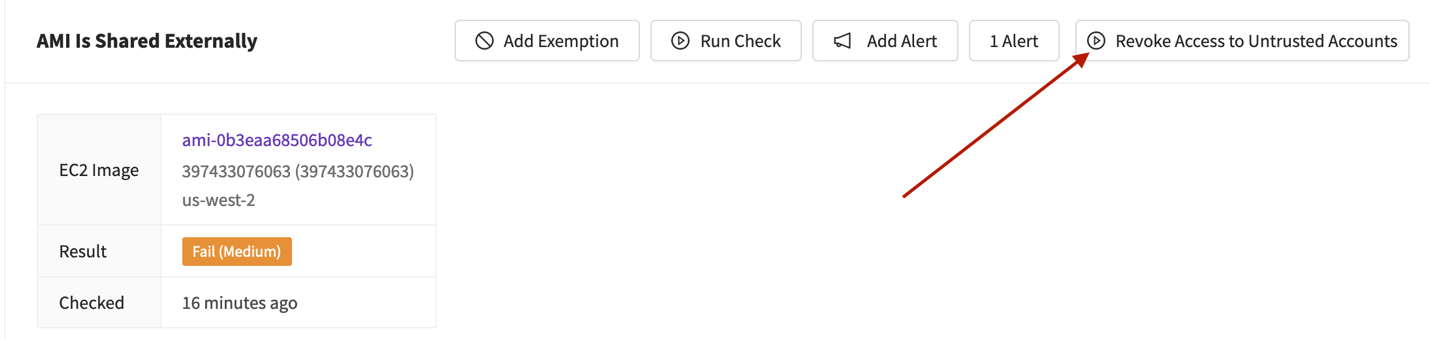
Okay, did we Stop the Bleed? We stopped… part of the bleed. We locked down the AMI, but we still don’t know how it ended up there. We also don’t know who owns that AWS account. Can we find out? Nope. If it isn’t ours, all we can do is report it to AWS and let them handle the rest.
Let’s hunt for the API calls to find out who shared it and what else they did. I’m going to do these next bits in the platform, but you would run queries in your SIEM or Athena to find the same information. I’ll do future posts on all the queries, but this post is focused on the sick/bleed concepts.
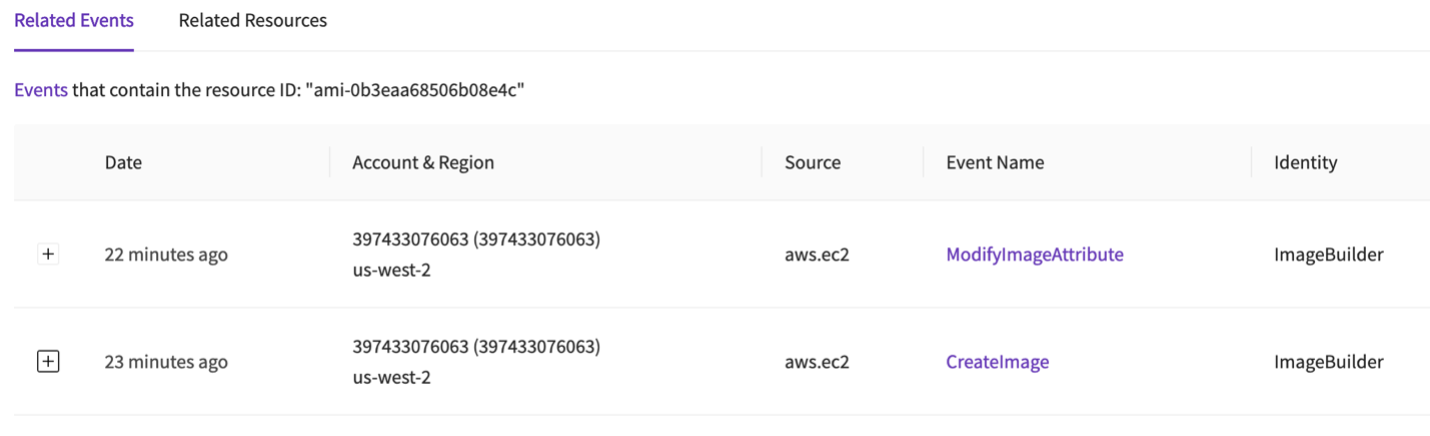
Okay- I see an IAM entity named ImageBuilder is responsible. Again, because this post is already running long, I checked a few things and here is what I learned:
- ImageBuilder is an IAM user with privileges to create images and modify their attributes, but nothing more. However, the policy has no resource constraints so it can create an image of any instance. And no conditional restraints so it can share with any account. This is a moderate to low blast radius- it’s over-privileged, but not horribly. I call it, sorta-sick.
- The API call came from an unknown IP address. This is suspicious, but still only sorta-sick.
- It is the first time I see that IP address used by this IAM user, and the user shows previous activity aligned with a batch process. Okay, now I’m leaning towards sick. Usually we don’t see rotating IP addresses for jobs like this, it smells of a lost credential:
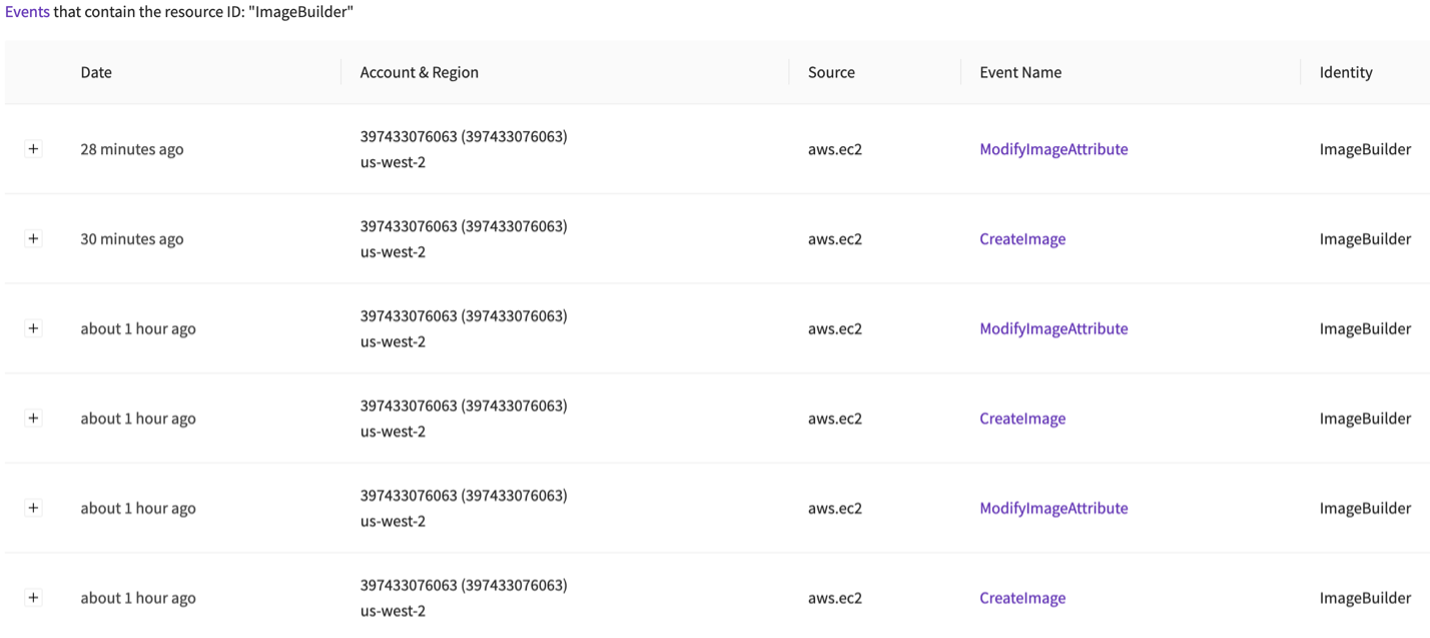
- That IAM user can continue to perform these actions. Unless someone tells me they meant to do this, I’m calling it Sick and I’m going to Stop the Bleed and put an IAM restriction on that user account (probably a Deny All policy unless this is a critical process, and then I’d use an IP restriction).
In summary:
- I found an AMI shared to an unknown account: Sick
- That AMI was for a production asset: Sick and Stop the Bleed
- The action was from an IAM user with wide privileges to make AMIs and share them, but nothing else: Maybe sick, still investigating.
- The IAM user made that AMI from an unknown, new IP address: Sick, Stop the (rest of the) Bleed.
- There is no other detected activity from the IP address: Likely contained and no longer Sick
- I still don’t know how those credentials were leaked: Sick, and time to call in our traditional IR friends to see if it was a network or host compromise.
I went through this quickly to highlight how I think of these issues. With just a few differences this same finding would have been totally normal. Imagine we realized it was shared with a new account we control but wasn’t registered yet. Or the AMI was for a development instance that doesn’t have anything sensitive in it. Or the API calls came from our network, at the expected time, or from an admins system and they meant to share it. This example is not egregious, but it is a known form of data exfiltration used by active threat actors. As I find each piece of information I evaluate if it’s Sick or Not Sick and if I need to Stop the Bleed.
How is this different in cloud? Because the stakes are higher when everything potentially touches the Internet. We need to think and act faster, and I find this memory aid helpful, to keep us on track.