

There are multiple techniques for containing compromised instance credentials. The easy ones are the most likely to break things, but there are creative options to lock out attackers without breaking applications.
Over the past few years we’ve seen some major advances by Amazon to help reduce the risks that an attacker can steal and abuse credentials assigned to AWS instances. Okay, sure, a lot of this happened after that really big breach that everyone still talks about, but we now have much better tools to prevent this kind of attack. That said, it’s still very common and high up on everyone’s cloud threat list.
Last month AWS released some new policy options to lock down instance credentials which spurred the idea for this post. That and an interesting discovery out of the cloud security community that I’ll talk about in a minute. As great as this new capability is, combined with AWS dramatically improving their GuardDuty detections for credential exfiltration, at some point you might get an alert from a tool like ours and have to kick your incident response process into gear:
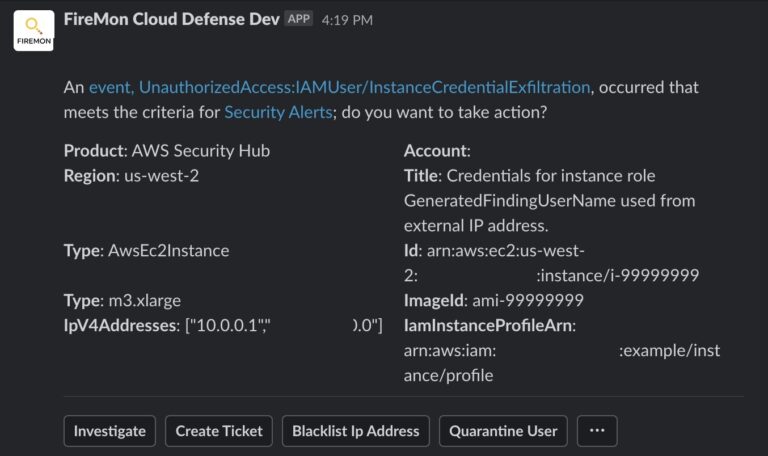
Over the years I’ve compiled and tested a host of containment options, most of which I have labs for in the cloud incident response training I put together with Will Bengtson. There is a surprising amount of nuance to ensuring that you are able to contain the attacker without breaking things. When working with instance credentials you effectively are interacting with three components: the IAM service which handles the permissions, the Instance Metadata Service (IMDS) that handles passing those credentials to the instance, and the code/SDK running your application inside the instance that uses the credentials. Note that I am deliberately simplifying some things and am ignoring Service Control Policies and Resource (bucket) policies. (All of the screenshots in this post are brazenly stolen from my own training, so please don’t report me to the authorities.)
And quick background for those that don’t know, when you assign an instance an IAM role, that instance is provided automatically rotating credentials that give it the permissions of that role. But if an attacker can access the instance in some way, such as an SSRF attack or brute forcing SSH, they can copy those credentials and use them outside of AWS or from an AWS account under their control.
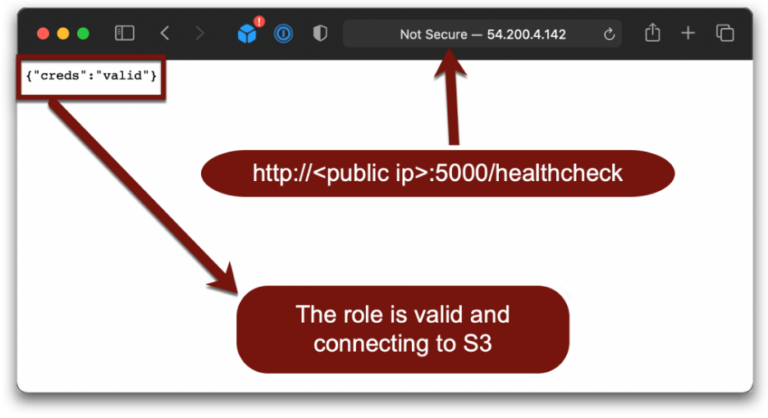
As setup, Will wrote a small application that tries to make an internal connection to an S3 bucket and reports back if the credentials are valid (no, the shown IP addresses are no longer valid):
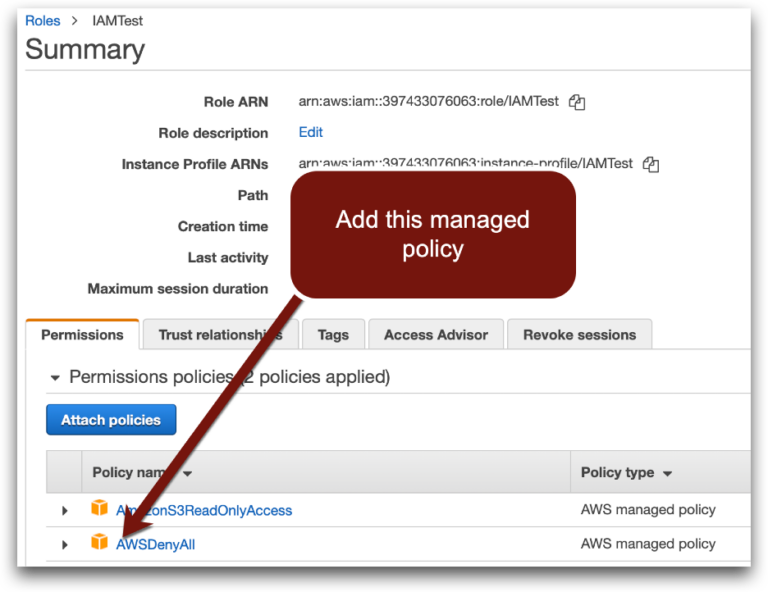
Option 1: Add a Deny All Policy to the Role
This is, by far, the easiest and fastest. By adding a Deny All policy to the IAM role all API calls will fail and the attacker can’t cause any more damage.
It’s fast, easy, and a really quick way to break your application since this will stop any legitimate API calls:
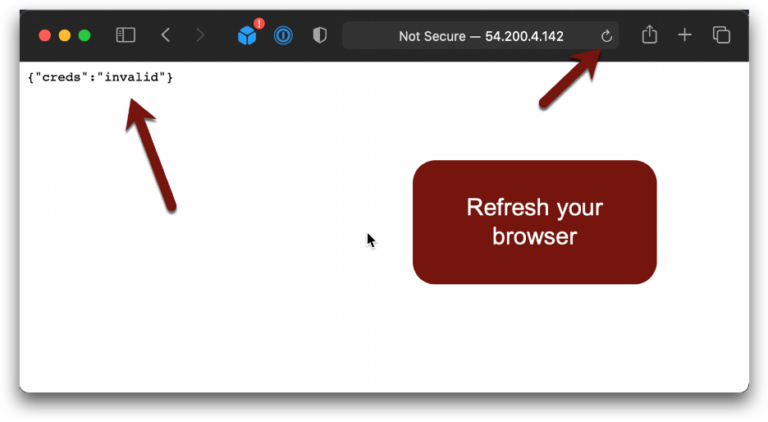
Remember, our objective is to keep the attacker out without breaking our legitimate running applications.
Oops.
Option 2: Revoke the Session
AWS has a cool feature for revoking active sessions. With the click of a button in the console you can add custom Deny All policy that only denies access for any sessions started before the time set when you click the button (there’s no simple API call for this, but it isn’t hard to write your own policy to do the same thing).
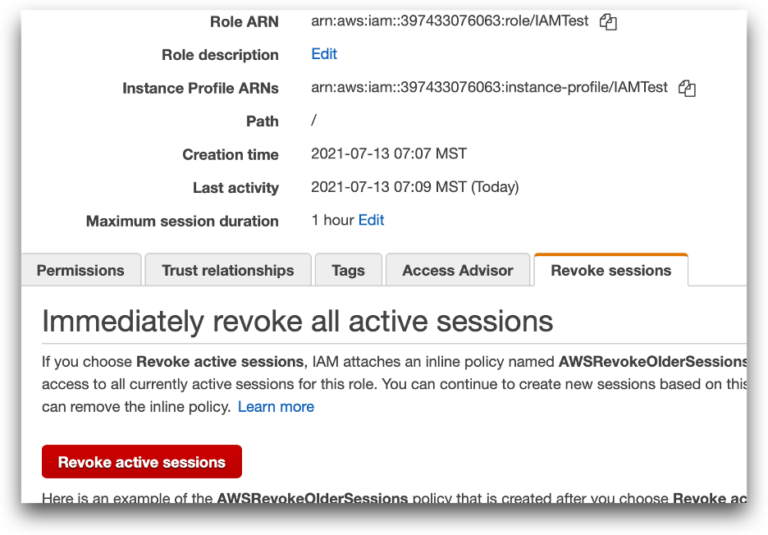
Now assuming you blocked the attacker from compromising the new session, in theory this would lock them out by expiring the stolen credentials and let your application work with new ones. But…
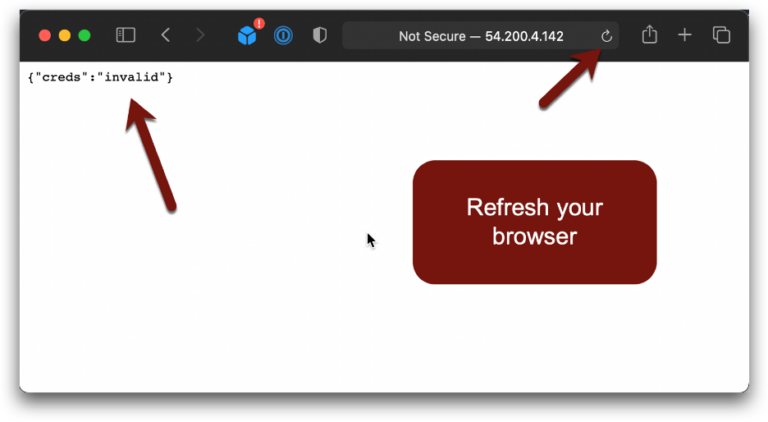
Nope. Oopsie number 2. Why?
The IMDS will only update the credentials when they expire. IMDS is a different service from IAM and doesn’t know that you revoked credentials and it has no reason, or motivation, to pull the new credentials and provide them to the instance. It will keep serving the revoked credentials until the end of the session.
Option 3: Change the IAM Role and Deny the Old Role
Now we start to get fancy. What if we create a new role and change the instance to use the new one and block the old one? As before, this would only work if you know the attacker can’t just steal the new role’s credentials.
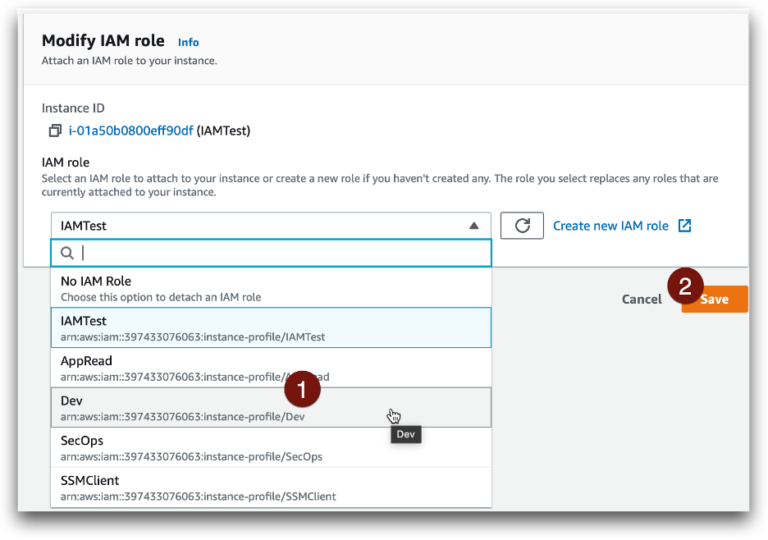
Nope. Oopsie number 3. So what’s going on here?
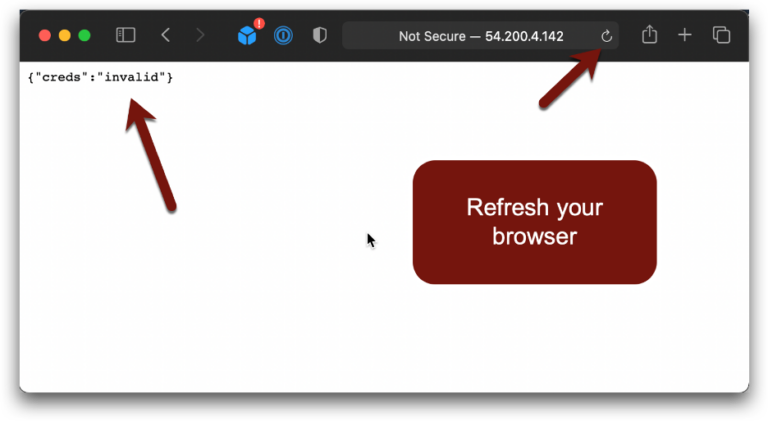
Most of the code and SDKs will establish an IAM session when they start and pull the credentials from the metadata service. These credentials have a session duration, which is like a Time to Live (TTL). The credentials are kept in-memory and used until near the end of the duration. For example, using the Boto library in Python (which we did for this demo) the code won’t look for new credentials until 15 minutes before the credential expiration.
Thus the application will keep failing until it looks for updated credentials. Depending on how things are set up this will tend to default to every 6 hours in an EC2 instance. Okay, maybe you have awesome developers with excellent error handling that will try and pull new credentials on a failed API call, but that’s unlikely since it isn’t a common use case.
The code in the instance is still trying to use the old role because it doesn’t know any better. In option 2 we broke things because the IMDS didn’t know to check with IAM to update credentials. This time the code doesn’t know to talk to IMDS to get new credentials.
Option 4: Insert a VPC Endpoint
This one was me getting fancy, and it is by far the most complicated, but it works very well. All instances live in a VPC (Virtual Private Cloud) which is their virtual network in AWS. Normally all API calls go out over the Internet to reach the public AWS endpoints. In fact, if you have an instance in a private subnet without an outbound route to the Internet those API calls will fail.
Well, that’s kind of a big problem if you want your own private instance to talk to your own private S3 bucket. We used to have to enable Internet access, which has costs and opens things up in ways we security professionals like to minimize.
Amazon’s answer is known as a Service Endpoint. These are internal, software-defined routing structures you can configure to allow resources in a VPC to talk to API endpoints (and other things, but this isn’t the post to get into that) all on Amazon’s internal network. The cool thing is that when you use a VPC endpoint AWS inserts some additional context into the network traffic since it can now embed data in their private headers, and we can use this as conditions in our IAM policies!
First we add a VPC endpoint for S3 to the subnet our instance is in:
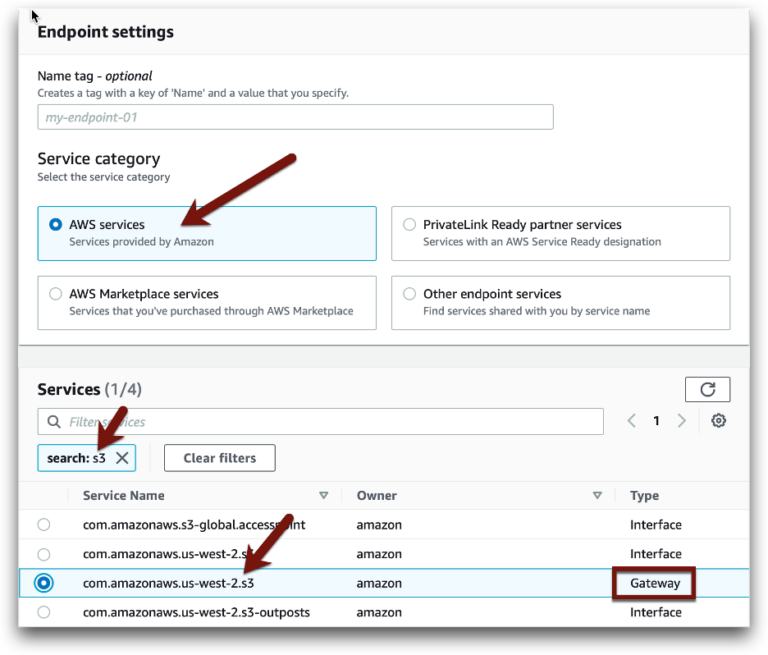
Then we add a condition to our IAM policy that denies all traffic if it doesn’t come from the expected VPC. This is how we do it in the training lab:
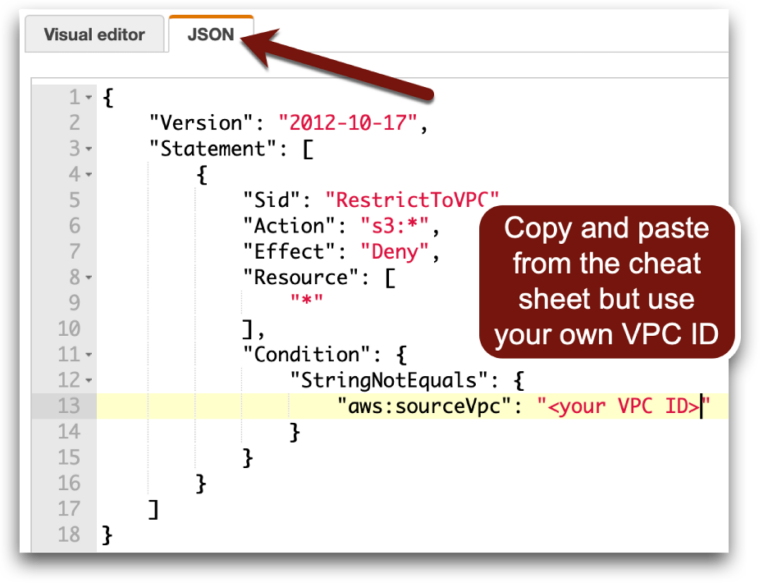
If this works, API calls from our instance will still work but the credentials will fail if used from anywhere other than this VPC (so let’s hope the attacker doesn’t have access to another resource in the VPC).
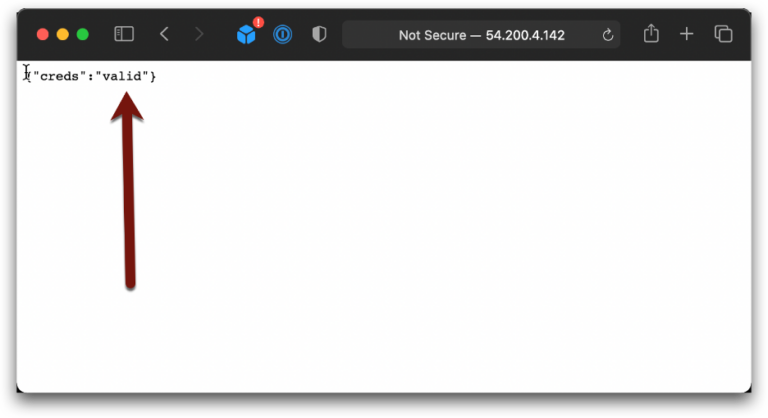
Woo Hoo! Our credentials will only work from within the VPC and the attacker is locked out. This is EXACTLY how that Service Control Policy I mentioned up above works. The problem with the SCP is that service endpoints add cost and complexity and turning on that policy without having all the right endpoints in place will break things, but now at enterprise scale.
An Unexpected Behavior
As I mentioned we built this lab about 2 years ago and have run a couple hundred students through it. Last week Andre Rall from Uptycs posted the following in a cloud security community we both participate in (used with permission):
Does anyone know if this should be happening? I have a role attached to an instance profile which is associated to an instance. When I remove the role from the instance profile (via CLI) but keep the instance profile associated with the instance, the instance is still able to use the credentials from the role. My brain is telling me because the role is not attached, the instance should not be able to continue using it, but maybe I’m missing something.
It turns out we run into that service interaction again. Behind the scenes an instance profile is what AWS uses to link a role to an instance in the metadata service. Adre removed the role from the instance profile, but the role still exists and the instance profile still exists.
You would think the IMDS would not be able to serve the credentials, but it still HAS the credentials and doesn’t know what happened over in the IAM service. It still serves the credentials and the role still allows the credentials so they still work. Revoking the credentials WOULD work in this case because the IMDS would not be able to get the new credentials after the instance profile and the role are decoupled.
Containing IAM credentials has a lot of nuance, and this is only one set of examples from one service (EC2). But once you see the flow of the IAM service interacting with the IMDS interacting with SDKs you will get a firm foundation in some of the core principles you can use in other situations.
And don’t forget to check out the FireMon Cloud Defense Free-Tier we just launched.